
Anand Sambamoorthy
Solutions Architect, Engineer
Messaging At Ease - Powered by Kafka!
Published Feb 23, 2020
I have exposure to traditional enterprise wide deployed messaging systems (typically JMS based and some AMQP based at later stages). Kafka was only experimentational to see if it was a fit-for-purpose tool for the use-cases at hand. This blog is part of the refresher and my reading through newer messaging technology - Kafka. The idea is to implement a sample use-case and to compare and see the features that Kafka brings to the table comparing against typical messaging technologies (JMS). The idea is not to list the difference from the Kafka platform and architecture perspective - e.g. distributed, scalable nature; rather it is to list the features that are from Message-Producer/Consumer perspective.
Kafka
Kafka is a high throughput distributed messaging platform typically used as a transport mechanism. Note: It is not typically used as application processing tool with business rules except when combined with kafka-streams where you can do some application processing logic. (it is claimed that it can infact be an alternative to processing frameworks like Apache-Spark)
Typical use-cases for using Kafka
- Messaging and decoupling systems
- Activity gathering
- Metrics gathering from different locations, systems
- Application logs gathering
- Stream processing
- Typically used in micro-services architecture, big-data integration along side with spark(some change this newly introduced streams)
Application implementation
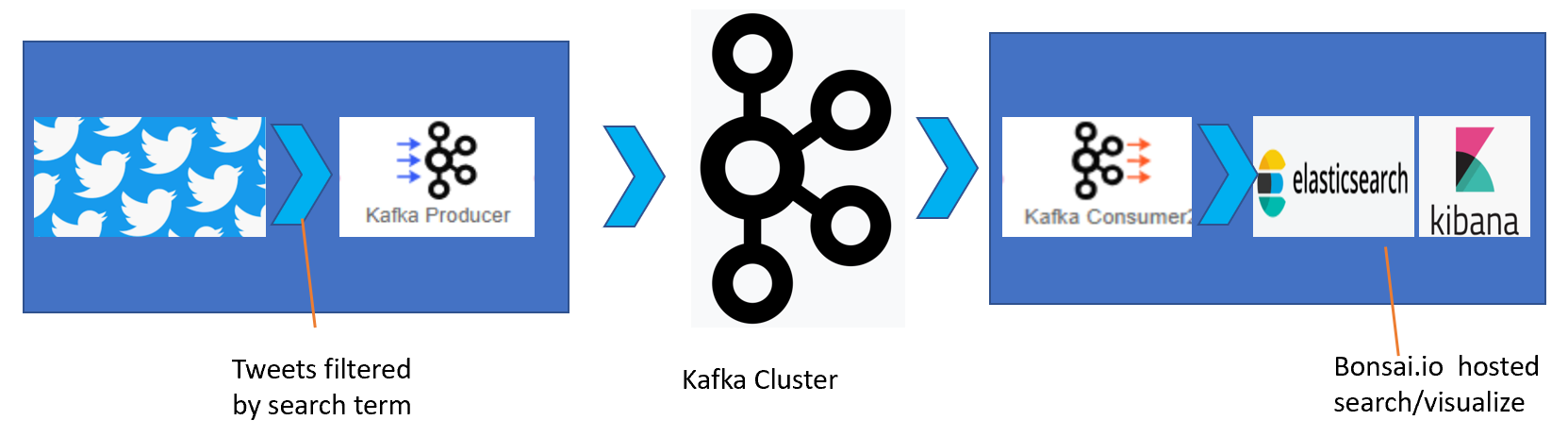
The sample application would source tweets from twitter publish to a kafka cluster and sinked to an elasticsearch and visualization setup in Kibana. Application setup steps:
- Install and configure Kafka with a tweets_topic
- Source data from twitter - java client connecting to the twitter app with required auth keys
- Sourced tweets published to Kafka
- Consume tweets from Kafka topic with consumer/consumer-groups
- Sink them to elastic-search cluster
- Setup visualization with Kibana Note: Elastic cluster and Kibana are setup on cloud hosted bonsai.io
Application Design:-
Features that caught me
Below listing are the features from the Message Producer, Consumer point of view. The listing does not talk about Kafka from the overall platform and architecture point of view like cluster configuration, brokers (bootstrap brokers) partitions, replication etc!
- Idempotent Producer
- An out of the box feature offered by Kafka - where the messaging system (the broker) is intelligent enough to know that it has already seen the message and discards it as duplicate. This occurs when for some reason the message-producer re-sends the message (say the n/w failed when the message-broker was sending a JMS-Ack and the producer re-sends the message). This is not a out-of-box feature that JMS message-brokers have by default atleast; the onus lies with the subscription system rather to discard them.
- Safe Producer
- A safe-producer (retry, acks etc) in Kafka is a configurable feature setup at a message-producer level rather than the configuration on a broker/destination level.
- This is a good one especially if we think that it is best known for a producer to know the criticality of the message rather than at a broker/destination level. e.g on a notification topic - say the message producer with information notification does not need to have the Acks from all the broker partitions.
Producer{
...
//safe producer
properties.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
properties.setProperty(ProducerConfig.ACKS_CONFIG, "all");
properties.setProperty(ProducerConfig.RETRIES_CONFIG, "100");
properties.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, "5");//use 1 for ordering and that is within the partition
...
}
- Optimize for ThroughPut - producer level
- Kafka lets the Message producer decide how best to optimize the throughput of the message by setting properties e.g compression choice - say use google-snappy rather than simple zip and batching of the messages.
- This is a nice feature especially if we take the specialized
approach like earlier that the message-producer knows the message
and decided how best to batch, compress to increase throughput.
Producer{
...
//High thruput settings
properties.setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "20");
properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, Integer.toString(32 * 1024));
...
}
- Idempotent Consumer
- Idempotent consumer is a feature that removes the burden from applications implementing logic to detect duplication. Kafka-consumers can be configured with ids (business key or a combination of say topic_partition_somekey) that the kafka message broker will use to detect and purge the duplicate messages. Note: Typical JMS/AMQP implementations like ActiveMQ has these features as well, so not a unique feature but a nice out of box configurable feature.
- Consumer in control
- The polling behaviour of Kafka lets consumers configure how best to retrieve the messages from the kafka-cluster. Consumer by configuration are empowered to poll data for batches at defined intervals or with batch-size exceeding certain limit rather than getting the messages as it is published.
- The idea is the consumer is best to judge how to consumer rather than the broker just pushing the messages as they get published
- Commits and the bulk requests
- Message commits have choice - auto-commit or by consumers deciding when to commit.
- While this is not a new feature of Kakfa - this give more choices with configurable features like commit after bulk-request, batch.
- This feature also enables consumers to use Kafka as a persistent mechanism - to retrieve data at will from the point of choice. Kafka can re-play the messages on a commit-reset and the consumer can simply process them again. This is not something available with the typical messaging systems - the messages once delivered-acknowledged are gone from the broker. The onus lies with the publishing system to re-create/publish them again or the consumer get them by other choices with IT support intervention.
In summary, Kafka seems a great choice for messaging that empowers Message Producers and Message Consumers to decide how and when they want to pub/sub messages which is a bit different from typical messaging systems which does not have a great deal of flexibilty- the QoS of typical systems are often dictated/configured at a broker/destination level.
This added to the architecture, platform, monitoring, security and management features that Kafka as a whole offers makes Kafka a powerful platform for messaging and at ease. [why ease? I could setup the application that I described earlier in my laptop in a matter for few hours and it works!]